Building the objects you need
To implement data piping in an application, you’ll
need to build a few different objects:
- A Pipeline object
- A supporting user object
- A window
Building a Pipeline object
You must build a Pipeline object to specify the data definition
and access aspects of the pipeline that you want your application
to execute. Use the Data Pipeline painter in PowerBuilder to create
this object and define the characteristics you want it to have.
Characteristics to define
Among the characteristics you can define in the Data Pipeline
painter are:
- The source
tables
to access and the data to retrieve from them (you
can also access database stored procedures as the data source) - The destination table
to which
you want that data piped - The piping operation
to perform
(create, replace, refresh, append, or update) - The frequency of commits
during
the piping operation (after every n
rows are
piped, or after all rows are piped, or not at all–if you
plan to code your own commit logic) - The number of errors
to allow
before the piping operation is terminated - Whether or not to pipe extended attributes
to
the destination database (from the PowerBuilder repository in the
source database)
For full details on using the Data Pipeline
painter to build your Pipeline object, see the PowerBuilder User’s
Guide
.
Example
Here’s an example of how you would the Data Pipeline
painter to define a Pipeline object named pipe_sales_extract1
(one of two Pipeline objects employed by the w_sales_extract
window in a sample order entry application).
The source data to pipe This Pipeline object joins two tables (Sales_rep and
Sales_summary) from the company’s sales database
to provide the source data to be piped. It retrieves just the rows
from a particular quarter of the year (which the application must
specify by supplying a value for the retrieval argument named quarter
):

Notice that this Pipeline object also indicates specific columns
to be piped from each source table (srep_id, srep_lname,
and srep_fname from the Sales_rep table, as well
as ssum_quarter and ssum_rep_team from
the Sales_summary table). In addition, it defines a computed
column to be calculated and piped. This computed column subtracts
the ssum_rep_quota column of the Sales_summary
table from the ssum_rep_actual column:

How to pipe the data The details of how pipe_sales_extract1 is
to pipe its source data are specified here:
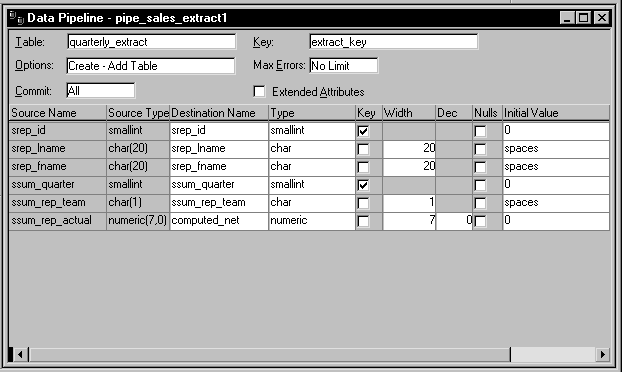
Notice that this Pipeline object is defined to create a new
destination table named Quarterly_extract. A little later
you’ll learn how the application specifies the destination
database in which to put this table (as well as how it specifies
the source database in which to look for the source tables).
Also notice that:
- A commit
will
be performed only after all appropriate rows have been piped (which
means that if the pipeline’s execution is terminated early,
all changes to the Quarterly_extract table will be rolled
back) - No error limit
is to be imposed
by the application, so any number of rows can be in error without
causing the pipeline’s execution to terminate early - No extended attributes
are
to be piped to the destination database - The primary key
of the Quarterly_extract
table is to consist of the srep_id column and the ssum_quarter
column - The computed column
that the
application is to create in the Quarterly_extract table
is to be named computed_net
Building a supporting user object
So
far you’ve seen how your Pipeline object defines the details
of the data and access for a pipeline. But a Pipeline object doesn’t
include the logistical supports–properties, events, and
functions–that an application requires to handle pipeline
execution and control.
About the Pipeline system object
To provide these logistical supports, you must build an appropriate
user object inherited from the PowerBuilder Pipeline system
object. This system object contains various properties,
events, and functions that enable your application to manage a Pipeline
object at execution time. These include:
| Properties | Events | Functions |
|---|---|---|
| DataObjectRowsReadRowsWrittenRowsInErrorSyntax | PipeStartPipeMeterPipeEnd | StartRepairCancel |
A little later in this chapter you’ll learn how to
use most of these properties, events, and functions in your application.
![]() To build the supporting user object for a pipeline:
To build the supporting user object for a pipeline:
-
Select Standard Class from the Object tab
of the New dialog box.The Select Standard Class Type dialog box displays, prompting
you to specify the name of the PowerBuilder system object (class)
from which you want to inherit your new user object:
- Select pipeline and click OK.
-
Make any changes you want to the user object (although
none are required). This might involve coding events, functions,
or variables for use in your application.To learn about one particularly useful specialization
you can make to your user object, see “Monitoring pipeline
progress”. Planning ahead for reuse As you work on your user object, keep in mind that it can
Planning ahead for reuse As you work on your user object, keep in mind that it can
be reused in the future to support any other pipelines you want
to execute–it isn’t automatically tied in any
way to a particular Pipeline object you’ve built in the
Data Pipeline painter.To take advantage of this flexibility, make sure that the
events, functions, and variables you code in the user object are
generic enough to accommodate any Pipeline object. - Save the user object.
For more information on working with the User
Object painter, see the PowerBuilder User’s Guide
.
Building a window
One other object you need when piping data in your application
is a window. You’ll use this window to provide a user interface
to the pipeline, enabling people to interact with it in one or more
ways. These include:
- Starting
the
pipeline’s execution - Displaying and repairing
any
errors that occur - Canceling
the pipeline’s
execution if necessary
Required features for your window
When you build your window, you must include a DataWindow
control that the pipeline itself can use to display error rows (that
is, rows it can’t pipe to the destination table for some
reason). You don’t have to associate a DataWindow object
with this DataWindow control–the pipeline will provide
one of its own at execution time.
To learn about how you’ll work with
this DataWindow control in your application, see “Starting the pipeline “ and “Handling row errors “.
Optional features for your window
Other than that, you can design the window as you like. You’ll
typically want to include various other controls, such as:
- CommandButton
or PictureButton controls
to let the user initiate actions (such
as starting, repairing, or canceling the pipeline) - StaticText controls
to display
pipeline status information - Additional DataWindow controls
to
display the contents of the source and/or destination tables
If you need assistance with building a window,
see the PowerBuilder User’s Guide
.
Example
The following window handles the user-interface aspect of
the data piping in the order entry application. This window is named
w_sales_extract:

Several of the controls in this window are used to implement
particular pipeline-related capabilities. Here’s more information
about them:
| Control type | Control name | Purpose |
|---|---|---|
| RadioButton | rb_create | Selects pipe_sales_extract1 as the Pipeline object to execute |
| rb_insert | Selects pipe_sales_extract2 as the Pipeline object to execute |
|
| CommandButton | cb_write | Starts execution of the selected pipeline |
| cb_stop | Cancels pipeline execution or applying of row repairs |
|
| cb_applyfixes | Applies row repairs made by the user (in the dw_pipe_errors DataWindow control) to the destination table |
|
| cb_forgofixes | Clears all error rows from the dw_pipe_errors DataWindow control (for use when the user decides not to make repairs) |
|
| DataWindow | dw_review_extract | Displays the current contents of the destination table (Quarterly_extract) |
| dw_pipe_errors | (Required ) Used by the pipeline itself to automatically display the PowerBuilder pipeline-error DataWindow (which lists rows that can’t be piped due to some error) |
|
| StaticText | st_status_read | Displays the count of rows that the pipeline reads from the source tables |
| st_status_written | Displays the count of rows that the pipeline writes to the destination table or places in dw_pipe_errors |
|
| st_status_error | Displays the count of rows that the pipeline places in dw_pipe_errors (because they are in error) |